Distributed Neural Network Optimization
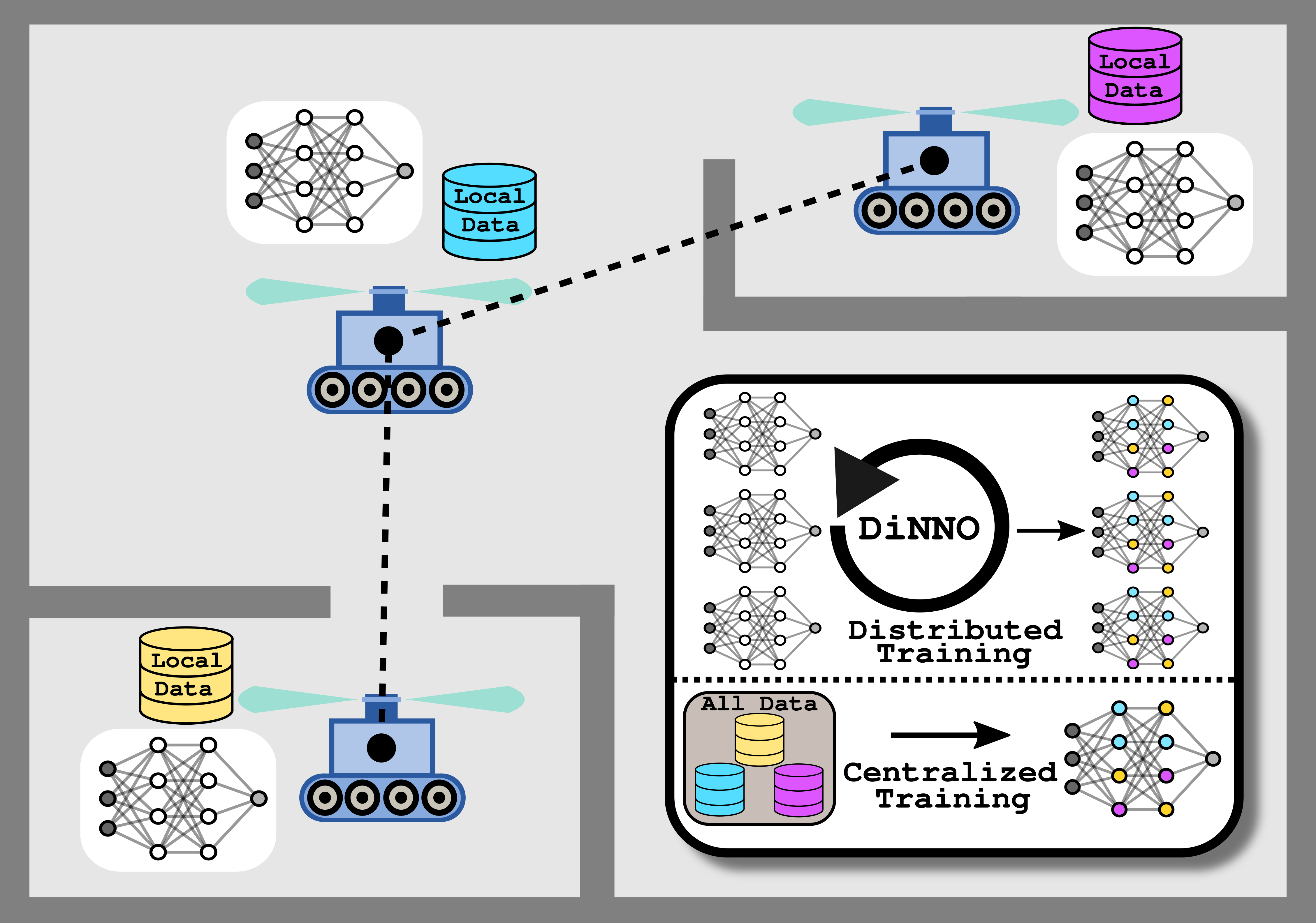
We present a distributed algorithm that enables a group of robots to collaboratively optimize the parameters of a deep neural network model while communicating over a mesh network. Each robot only has access to its own data and maintains its own version of the neural network, but eventually learns a model that is as good as if it had been trained on all the data centrally. No robot sends raw data over the wireless network, preserving data privacy and ensuring efficient use of wireless bandwidth. At each iteration, each robot approximately optimizes an augmented Lagrangian function, then communicates the resulting weights to its neighbors, updates dual variables, and repeats. Eventually, all robots’ local network weights reach a consensus. For convex objective functions, we prove this consensus is a global optimum. We compare our algorithm to two existing distributed deep neural network training algorithms in (i) an MNIST image classification task, (ii) a multi-robot implicit mapping task, and (iii) a multi-robot reinforcement learning task. In all of our experiments our method outperformed baselines, and was able to achieve validation loss equivalent to centrally trained models. Accompanying code for the paper can be found at https://github.com/javieryu/nn_distributed_training.